# LCSF Project
Presentation
The Light Command Set Format (LCSF) is a project aiming to facilitate application protocol development and deployment.
It consists of:
- A powerful serialization format and the software that implements it.
- A set of tools built on top to easily create and generate custom application protocols or remote procedure calls (RPC).
All the while, trying to strike a balance between wire efficiency, computation time and memory utilization. This allows LCSF to address everything from embedded systems to very large scale applications.
In the future, it could become an entire ecosystem with:
- Ready-made protocols for specific use cases.
- Out of the box applications based on those protocols.
Here is an overview of how it can be used:
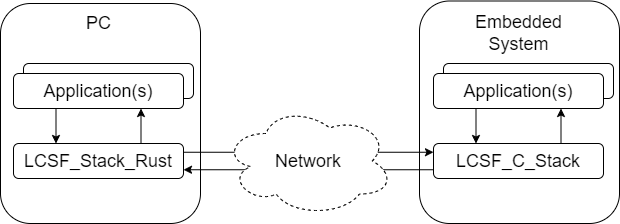
When to use
Whenever you’re developing an application where two systems need to automatically exchange data (send order, retrieve sensor measurements, status, reports…). You will often do so using a custom protocol made of commands and responses.
At its simplest, you can get away with sending ASCII characters, but when you start introducing data payloads that vary in length, or are optional, or when you have multiple conflicting versions of your protocol, it gets tedious to maintain real fast.
Maybe you’ll default to using gRPC or a RESTful API, which are resource-intensive and force you to use http/tcp whereas LCSF is lightweight and agnostic to any underlying network protocol.
In short, the LCSF project provides you the tools to simplify the tedious process of developing, deploying and maintaining your custom application protocols or RPCs. While being lightweight and network protocol agnostic.
LCSF features include:
- Ability to represent virtually any data complexity with infinitely branching attributes.
- Possibility to have many coexisting protocols on the same network.
- Automatically decode/encode messages and validate data payloads.
- GUI to safely generate/edit protocols and documentation, allowing you to iterate easily.
- Built-in error handling protocol.
Project components
The main components of the LCSF Project are:
- LCSF itself, which is:
- A specification to describe any application protocols.
- A lightweight format to represent those protocols and their commands.
- LCSF C Stack: An embedded-friendly LCSF implementation written in C, add it to your project to easily encode and decode LCSF messages.
- LCSF Stack Rust: A memory-safe LCSF implementation written in Rust.
- LCSF Generator: A C++/Qt graphic tool used to create, edit and deploy LCSF protocols. It generates code for the LCSF stacks and documentation (wiki and markdown format).
For more information on the other components, check their respective documentation.
Real-world examples
The following are two applications where LCSF was used:
- A protocol to update FPGA firmware binaries to a dozen distant microcontrollers, with integrity control.
- A protocol to stream the UI of a product (screen + buttons) between a microcontroller and a distant Linux computer. The core of the UI (hierarchy, texts, layouts…) being stored on the Linux for memory constraints.
LCSF Documentation
This is the documentation of the LCSF specification.
Protocol
A protocol in LCSF is the top hierarchical object. A protocol is composed of a number of commands.
Command Type
There are two types of commands:
- Simple commands, that are enough by themselves (e.g. ping, acknowledge, reset, abort…).
- Complex commands, that contain a data payload (e.g. a jump command that contains the jump address in its payload).
Command Payload
The command payload is a list of attributes (e.g. a send file command will contain, at least, a file size attribute and a file data attribute). Since attributes are here to structure the command payload, all attributes must have a data payload, otherwise they don’t have a reason to exist.
Command Direction
Your protocol might have a notion of master and slave or in more generic terms, a protocol asymmetry where there are two different point of view.
The way it is handled in LCSF is that you simply give each command a “direction”:
- (A -> B): A can only send the command, B can only receive it.
- (B -> A): B can only send the command, A can only receive it.
- (A <-> B) / Bidirectional: Both A and B can receive and send the command.
Attribute Type
There are two types of attributes:
- Simple attributes, that have data payload (e.g. a jump address attribute that contains the address itself).
- Complex attributes, that have a list of sub-attributes payload to describe more complex objects (e.g. a color space attribute that will contain as sub-attributes its type (RGB, YUV, HSL…) and its three components).
Sub-attribute
Sub-attributes are attributes in their own right. This means that if you have a data type Address in your protocol, you can use it as either an attribute or a sub-attribute.
Also, sub-attributes can have their own sub-attributes and there is no limit to the amount of attribute branching/nesting you can do. This is one of the key feature of LCSF and gives it the flexibility to describe any data payload that you may need to create your application protocol.
Optional Attribute
Attributes have a mandatory payload but there are cases where an attribute won’t be always there (e.g. a wait command may have a waiting time attribute or a default value if no time is given).
To avoid sending useless data, attributes can be set as optional, otherwise they’re mandatory.
Attribute Data Type
Simple attributes are given a data type to their payload. The different data types are:
(u)int8(u)int16(u)int32(u)int64float32float64StringByte Array
All the integer types have a maximum size of respectively 1, 2, 4 and 8 bytes. They use variable length encoding to remove unnecessary null value bytes during transmission.
Float32 are 4 bytes long and float64 8 bytes long.
Strings must be null-terminated, therefore their sizes are implicit.
Command Sequence
Protocols don’t have an intrinsic notion of sequences. This must be handled at the application level, using a state machine or something similar.
Good Practice
Creating your protocol and defining the different commands and attributes is not trivial and there is many ways to do one thing. This is why we propose the following good practices:
- To respect strict self-containment of protocol layers, if you have an attribute type of undetermined size like byte array (e.g. a file data attribute), you must accompany it with a size attribute (e.g. a
uint32oruint64file size attribute). One exception of this would be if you have fixed length array in your protocol (e.g. a SHA1 digest will always be 20 bytes) as the attribute itself will imply the size of the array. - An attribute can only appear once in a command or as a sub-attribute. Therefore, if you need to send multiple similar pieces of data, you should consider using an array attribute to regroup them.
- Complex attributes are costly, they take a few bytes to represent and a recursive call to process. You should only use them if the hierarchical data they carry has value and/or you don’t know in advance the data you want to send. For example, if you want to stream any file system with LCSF, both conditions are met.
Wrapping-up
The following diagram sums up how a LCSF protocol is structured:
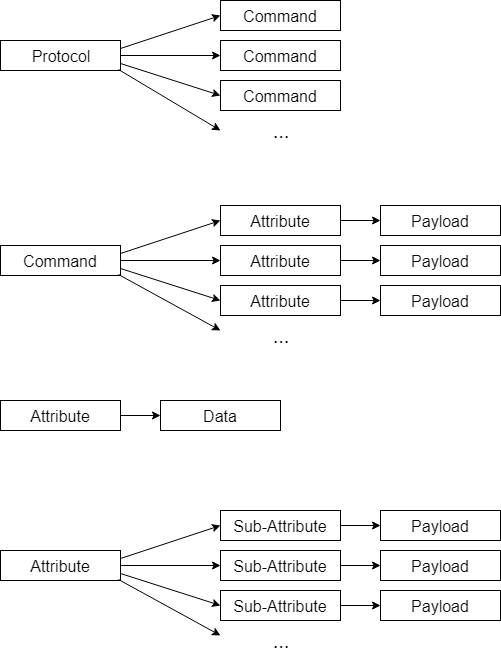
LCSF Message
As to how LCSF protocols are represented we need to distinguish two things:
- The protocol description, that represents all the commands and attributes that can be exchanged.
- A protocol message, that is the unit of data that will be transferred between a sender and a receiver. It will contains only one command and its attributes, if the command has any.
Protocol Description
The description format is language-dependent and will vary, but it will be based around arrays of structures, detailing the commands and their attributes.
Format Endianness
The format is little endian.
Identifier Space
Protocols, commands and attributes have separate identifiers spaces as they are considered different objects. Actually, every commands and attributes have their own (sub) attribute identifier space.
There is no problem with attributes of different commands having the same identifiers.
Protocol Message
The message structure is defined as:
- Protocol id: The user-defined protocol identifier. One id value (usually
~0) is reserved for the built-in LCSF error protocol. - Protocol version: The user-defined protocol version number (see Protocol Versioning). It lets a receiver reject a message coming from an incompatible version of the protocol.
- Command id: The user-defined command identifier of the command being sent.
- Attribute number: The command’s number of attributes.
- 1st Attribute id: The user-defined identifier of one of the command attributes.
- Complexity flag: Flag value is 0 if payload is data, 1 if sub-attributes.
- Payload size: Either the data size or the number of sub attributes, depending on complexity flag.
- Attribute payload.
- 2nd Attribute id.
- …
Simple Attribute structure:
- Attribute id
- Complexity flag
- Data size
- Data payload
Complex Attribute structure:
- Attribute id
- Complexity flag
- Sub-attributes number
- 1st sub-attribute id
- Complexity flag
- Payload size
- Sub-attribute payload
- 2nd sub-attribute id
- …
Wrapping-up
The following diagram sums up how a message is formatted:
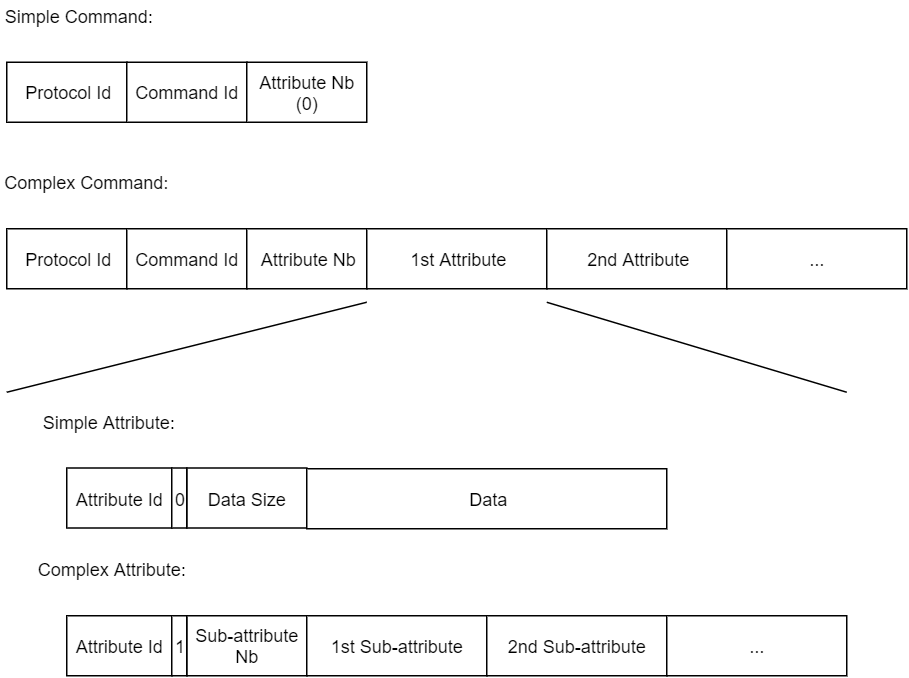
Standard representation
Below is the standard representation for the different LCSF message components:
- Protocol id:
16 bits,65535possible values -0xFFFFreserved for LCSF error protocol. - Protocol version:
16 bits,65536possible values. - Command id:
16 bits,65536possible values. - Attribute number:
16 bits, up to65535attributes per command. - Attribute id:
15 bits,32768possible values - MSB used by complexity flag. - Complexity flag.
1 bit,2values -0indicates a simple attribute and1a complex attribute. - Payload size:
16 bits, up to65535sub-attributes or bytes of data. - Data payload: User defined, in the limit of the payload size capabilities.
This means that small message sizes are:
- Simple command:
8 bytes. - Command with a simple attribute:
12 bytes + payload size.
Smaller representation
This smaller representation aims to reduce message overhead/size at the cost of representation space:
- Protocol id:
8 bits,255possible values -0xFFreserved for LCSF error protocol. - Protocol version:
8 bits,256possible values. - Command id:
8 bits,256possible values. - Attribute number:
8 bits, up to255attributes per command. - Attribute id:
7 bits,128possible values - MSB used by complexity flag. - Complexity flag.
1 bit,2values -0indicates a simple attribute and1a complex attribute. - Payload size:
8 bits, encodes up to255sub-attributes or bytes of data. - Data payload: User defined, in the limit of the payload size capabilities.
In this representation, small message sizes are:
- Simple command:
4 bytes. - Command with a simple attribute:
6 bytes + payload size.
Custom representations
If those representations don’t correspond to your application, you can create a custom one. In the future, other representations may be supported by the LCSF environment.
Protocol Versioning
You might run in a case where different systems will use different versions of the same protocol. If the different versions have the same identifier, it might lead to errors as one of the system might use a newer command that the other system doesn’t understand.
To handle this, every message carries a protocol version number, placed right after the protocol id (see Protocol Message). The version is defined per protocol and should be bumped whenever the protocol is changed after initial deployment.
On reception, the version is compared to the version expected by the receiver for that protocol. If they differ, the message is rejected and a BAD_PROTOCOL_VERSION error is reported (see LCSF Error Protocol). This lets incompatible versions be detected explicitly instead of causing silent misinterpretation of the payload.
LCSF Error Protocol
LCSF has a built-in error protocol to report problems encountered while processing incoming LCSF messages back to the sender.
To report errors at a protocol level (eg: valid command received at wrong step of a sequence), you should either have a dedicated error command in your protocol or a dedicated error protocol.
The protocol id is 0xFFFF (standard representation) and its protocol version is 0. It has only one command “Error” with two mandatory attributes “Error location” and “Error type”.
- Error location indicates if the message has bad formatting or if it doesn’t correspond to its protocol description
- Error type gives more information on the error nature
The tables below describe the protocol in more details.
Command description table:
| Command Name | Command Id | Direction | Attributes (mandatory) | Attributes (optional) | Description |
|---|---|---|---|---|---|
Error |
0x00 |
A <-> B |
Error_Location, Error_Type |
/ |
Indicates an error occurred when decoding a LCSF message |
Attribute description table:
| Attribute | Attribute Id | Data Type | Description |
|---|---|---|---|
Error_Location |
0x00 |
uint8 |
Enum describing the error location (bad formatting or protocol issue) |
Error_Type |
0x01 |
uint8 |
Enum describing the type of error |
Error_Location enum table:
| Enum name | Enum Value | Description |
|---|---|---|
DECODE_ERROR |
0x00 |
Error happened while decoding (formatting error) |
VALIDATION_ERROR |
0x01 |
Error happened while validating (protocol error) |
Error_Type enum table if decode error:
| Enum name | Enum Value | Description |
|---|---|---|
FORMAT_ERROR |
0x00 |
Message format error, missing or leftover bytes |
OVERFLOW_ERROR |
0x01 |
Message is too big to be processed |
UNKNOWN_ERROR |
0xFF |
Unspecified error |
Error_Type enum table if validation error:
| Enum name | Enum Value | Description |
|---|---|---|
UNKNOWN_PROTOCOL_ID |
0x00 |
Unrecognized protocol id |
UNKNOWN_COMMAND_ID |
0x01 |
Unrecognized command id |
UNKNOWN_ATTRIBUTE_ID |
0x02 |
Unrecognized attribute id |
TOO_MANY_ATTRIBUTES |
0x03 |
More attributes received than expected |
MISSING_NON_OPTIONAL |
0x04 |
A non optional attribute is missing |
WRONG_DATA_TYPE |
0x05 |
Attribute data is of wrong type/size |
BAD_PROTOCOL_VERSION |
0x06 |
Message protocol version doesn’t match the expected version |
UNKNOWN_ERROR |
0xFF |
Unspecified error |